Connecting Multiple Computers
 Image courtesy of Helena Lopes from Unsplash
Image courtesy of Helena Lopes from UnsplashDistributed Memory Architecture
Because of the difficulty of having very large numbers of CPU-cores in a single shared-memory computer, all of today’s supercomputers use the same basic approach to build a very large system: take lots of separate computers and connect them together with a fast network.

The most important points are:
- every separate computer is usually called a node
- each node has its own memory, totally separate from all the other nodes
- each node runs a separate copy of the operating system
- the only way that two nodes can interact with each other is by communication over the network.
For the moment, let’s ignore the complication that each computer is itself a shared-memory computer, and consider one processor per node.
The office analogy can be further extended: a distributed-memory parallel computer has workers all in separate offices, each with their own personal whiteboard, who can only communicate by phoning each other.
| Advantages |
|---|
| The number of whiteboards (i.e. the total memory) grows as we add more offices. |
| There is no overcrowding so every worker has easy access to a whiteboard. |
| We can, in principle, add as many workers as we want provided the network can cope. |
| Disadvantages |
|---|
| If we have large amounts of data, we have to decide how to split it up across all the different offices. |
| We need to have lots of separate copies of the operating system. |
| It is more difficult to communicate with each other as you cannot see each others whiteboards so you have to make a phone call. |
The second disadvantage on this list doesn’t have any direct cost implications as almost all supercomputers use some version of the Linux OS which is free but, it does mean thousands of copies of the OS, or other installed software, need to be upgraded when updates are required.
Building networks to connect many computers is significantly easier than designing shared-memory computers with a large number of CPU-cores.
This means it is relatively straightforward to build very large supercomputers - it remains an engineering challenge, one that computer engineers excel at solving.
So, if building a large distributed-memory supercomputer is relatively straightforward then we’ve cracked the problem?
Well, unfortunately not. The compromises we make (many separate computers each with their own private memory) mean that the difficulties are now transferred to the software side.
Having built a supercomputer, we now have to write a program that can take advantage of all those thousands of CPU-cores.
This can be quite challenging in the distributed-memory model.
Why do you think the distributed memory architecture is common in supercomputing but is not used in your laptop?
 Image courtesy of
Image courtesy of Simple Parallel Calculation
Let’s return to the income calculation example. This time we’ll be a bit more ambitious and try and add up 800 salaries rather than 80.
The salaries are spread across 8 whiteboards (100 on each), all in separate offices
Here we are exploiting the fact that distributed-memory architectures allow us to have a large amount of memory.
If we have one worker per office, think about how you could get them all to cooperate to add up all the salaries. Consider two cases:
- only one boss worker needs to know the final result;
- all the workers need to know the final result.
To minimise the communication-related costs, try to make as few phone calls as possible.
 © ARCHER2
© ARCHER2Case study of a real machine
To reinforce the concepts we have introduced in this course, we’ll now look at a specific supercomputer, the UK National Supercomputer, ARCHER2, as a concrete example.
This machine has a relatively straightforward construction and is therefore a good illustration of supercomputer hardware in general.
General
Archer2 is a HPE Cray EX machine, built by American supercomputer company Cray, a Hewlett Packard Enterprises company. It contains 750,080 CPU-cores and has a theoretical performance of 28 Pflop/s. It is operated by EPCC at the University of Edinburgh on behalf of EPSRC and NERC, and is the major HPC resource for UK research in engineering and in physical and environmental science.
Node design
The basic processor used in ARCHER2 is the AMD Zen2 (Rome) EPYC 7742 CPU, which has a clock speed of 2.25 Ghz . The nodes on ARCHER2 have 128 cores across two of the AMD processors. All the cores are under the control of a single operating system. The OS is the HPE Cray Linux Environment, which is a specialised version of SUSE Linux.
Network
The complete ARCHER2 system contains 5,860 nodes, i.e. ARCHER2 is effectively 6,000 seperate computers each running their own copy of Linux. They are connected by the HPE Slingshot interconnect, which has a complicated hierarchical structure specifically designed for supercomputing applications. Each node has two 100 Gb/s network connections, this means each node has a network bandwidth 2048 times faster than what is possible over a 100 Mb/s fast broadband connection!
System performance
ARCHER2 has a total of 750,080 CPU-cores: 5,860 nodes each with 128 CPU-cores. With a Clock frequency of 2.25 Ghz, the CPU-cores can execute 2.25 billion instructions per second. However, on a modern processor, a single instruction can perform more than one floating-point operation.
For example, on ARCHER2 one instruction can perform up to four separate additions. In fact, the cores have separate units for doing additions and for doing multiplications that run in parallel. With the wind in the right direction and everything going to plan, a core can therefore perform 16 floating-point operations per cycle: eight additions and eight multiplications.
This gives a peak performance of 750,080 * 2.25 * 16 Gflop/s = 27,002,880 Glop/s, agreeing with the 25.8 Pflop/s figure in the top500 list.
ARCHER2 comprises 23 separate cabinets, each about the height and width of a standard door, with around 32,768 CPU-cores (256 nodes) or about 60,000 virtual cores (using multi-threading) in each cabinet.
 © EPCC
© EPCCStorage
Most of the ARCHER2 nodes have 256 GByte of memory (some have 512 GByte), giving a total memory in excess of 1.5 PByte of RAM.
Disk storage systems are quite complicated, but they follow the same basic approach as supercomputers themselves: connect many standard units together to create a much more powerful parallel system. ARCHER2 has over a 15 PByte of Disk storage.
Power and Cooling
If all the CPU-cores are fully loaded, ARCHER2 requires in excess of 4 Megawatts of power, roughly equivalent to the average consumption of around 4000 houses.
This is a significant amount of power to mitigate the associated environmental impact, ARCHER2 is supplied by a 100% renewable energy contract.
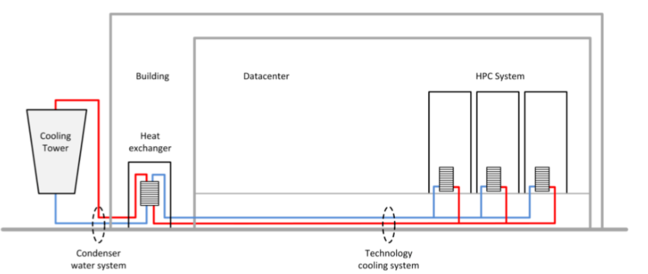
The ARCHER2 cabinets are cooled by water flowing through pipes, with water entering at 18°C and exiting at 29°C.
The heated water is then cooled and re-circulated.
When necessary the water is cooled by electrical chillers but, most of the time, ARCHER2 can take advantage of the mild Scottish climate and cool the water for free simply by pumping it through external cooling towers, so saving significant amounts of energy.
 © Mike Brown
© Mike Brown ARCHER’s cooling towers © Mike Brown
ARCHER’s cooling towers © Mike BrownWee ARCHIE case study
Finally, Wee ARCHIE makes its appearance again! This video uses Wee ARCHIE to explain the parallel computer architecture concepts we've introduced.
It is worth emphasising that the physical distance between the nodes does impact their communication time i.e. the further apart they are the longer it takes to send a message between them. Can you think of any reason why this behaviour may be problematic on large machines and any possible workarounds?
As usual, share your thought with your fellow learners!
For anyone interested in how Wee ARCHIE has been put together (and possibly wanting to build their own cluster), we invite you to follow the links from this blog article - Setting up your own Raspberry Pi cluster.


 Image courtesy of
Image courtesy of ARCHER2 - it's more complicated
In the last few steps we have glossed over a few details of the processors and the network.
If you look up the specifications of the AMD Zen2 (Rome) EPYC 7742 processor you will see that it has 64 CPU-cores, whereas the ARCHER2 nodes have 128 CPU-cores.
Each node contains two physical processors, configured to share the same memory. This design makes the system appear as a single 128-core processor to the user.
This setup, known as Non-Uniform Memory Access (NUMA) architecture, is illustrated below.
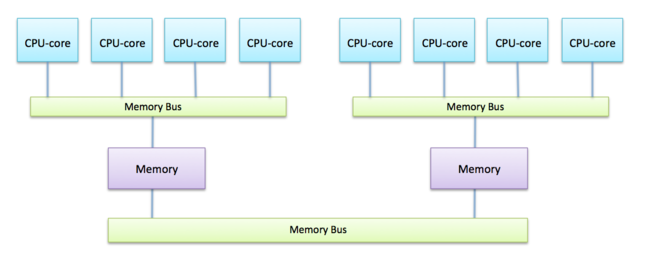
Every CPU-core can access all the memory regardless of which processor it is located on but, reading data from another CPU’s memory can involve going through an additional memory bus, making the process slower than reading from its own memory.
Although this hardware arrangement introduces technical complexities, the key point is that the 128 CPU-cores function as a single shared-memory system, managed by one operating system.
The details of the network are even more complicated with four separate levels ranging from direct connections between the nodes packaged together on the same blade, up to fibre-optic connections between separate cabinets. If you are interested in the details see the ARCHER2 website.
ARCHER2: building a real supercomputer
Wee ARCHIE is very small and was built on someone’s desk. Real supercomputers are very large and require a lot of infrastructure to support them and manpower to build them.
This time lapse video documents the installation of the ARCHER2 system at EPCC in Edinburgh, UK. We use it to pick out various aspects of supercomputer hardware that are not so well illustrated by Wee ARCHIE.
Is there anything that surprised you? We are curious to know so feel free share your impressions by leaving a comment.
Quiz - Processors, ARCHER2 and Wee ARCHIE
Connecting Parallel Computers Q1
Which of these are true about a typical processor in a modern supercomputer?
Select all the answers you think are correct.
A) it contains a single CPU-core
B) it contains many separate CPU-cores
C) it is a special processor, custom-designed for supercomputing
D) it is basically the same processor you would find in a high-end PC or compute server
Connecting Parallel Computers Q2
How are the CPU-cores attached to the memory in a modern multicore processor?
Select all the answers you think are correct.
A) the memory is physically sliced up between them
B) the memory is shared between all the CPU-cores
C) cores share access to the memory so they can sometimes slow each other down
D) each core can access the memory completely unaffected by the other cores
Connecting Parallel Computers Q3
Like almost all supercomputers, ARCHER2 is constructed as a series of separate cabinets (23 in the case of ARCHER2), each standing about as high and wide as a standard door. Why do you think this size of cabinet is chosen?
A) it is the minimum size that can be cooled effectively
B) it is the maximum size that can be run from a single power supply
C) any larger and the cabinets would not fit through the doors of the computer room
D) freight companies will not ship anything larger than this
Connecting Parallel Computers Q4
How are ARCHER2’s 750,080 cores arranged?
A) as one large shared-memory system
B) as 750,080 separate nodes
C) as 5,860 nodes each with 128 cores
D) as 11,720 nodes each with 64 cores
Connecting Parallel Computers Q5
Which of these features make the UK national Supercomputer ARCHER2 different from the toy system Wee ARCHIE?
Select all the answers you think are correct.
A) it has multicore CPUs
B) it has multiple nodes connected by a network
C) it runs the Linux operating system
D) it has a much faster network
E) it has many more CPU-cores