Parallelism in Everyday Computers
 Image courtesy of
Image courtesy of Computer Basics
Before we look at how supercomputers are built, it’s worth recapping what we learned previously about how a standard home computer or laptop works.
Things have become slightly more complicated in the past decade, so for a short while let’s pretend we are back in 2005 (notable events from 2005, at least from a UK point of view, include Microsoft founder Bill Gates receiving an honorary knighthood and the BBC relaunching Dr Who after a gap of more than a quarter of a century).
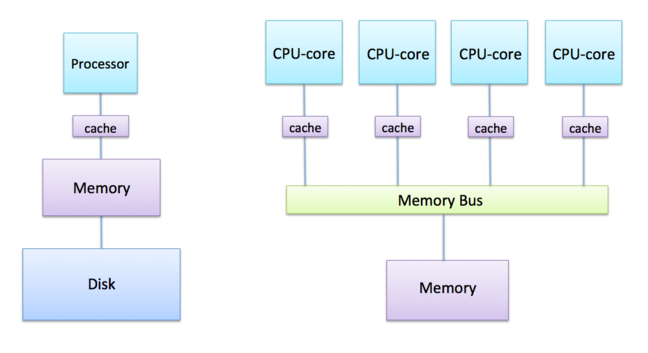
In 2005, a personal computer typically had three main components:
- A single processor for performing calculations.
- Random Access Memory (RAM) for temporary data storage.
- A hard disk for long-term storage of programs and files.
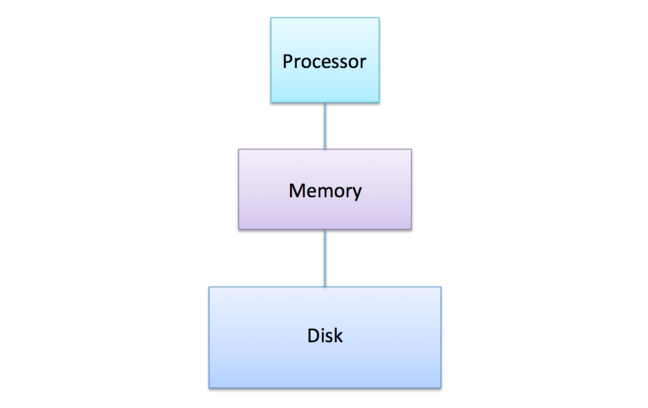
For our purposes, the configuration of memory is the most critical aspect, so we’ll set aside the hard disk for now.
The Rise of Multicore Processors
For three decades leading up to 2005, Moore’s Law ensured that processors became exponentially faster, primarily due to increasing CPU clock speeds. However, around 2005, clock speed growth plateaued at around 2 GHz.
The reason was simple: the amount of electrical power required to run processors at these speeds had become so large that they were becoming too hot for the domestic market (could not be cooled by a simple fan) and too expensive to run for the commercial market (large electricity bills and expensive cooling infrastructure).
So, around 2005, the application of Moore’s law changed: rather than using twice as many transistors to build a new, more complicated CPU with twice the frequency, manufacturers started to put two of the old CPUs on the same silicon chip - this is called a dual-core CPU.
The trend continued with four CPUs on a chip, then more … Generically, they are called multicore CPUs, although for very large numbers the term manycore CPU is now commonplace.
With multicore processors, terminology can be confusing.
When we refer to a "processor" or "CPU," it’s not always clear whether we mean the physical chip (which houses multiple processors) or the individual processing units within.
To avoid confusion in this course:
- CPU-core refers to each individual processing unit within a chip.
- CPU or processor refers to the entire multi-core chip.
So, a quad-core CPU (or quad-core processor) has four CPU-cores.
We now have two complementary ways of building a parallel computer:
- Shared-memory architecture: Build a single multicore computer using a processor with dozens of CPU-cores.
- Distributed-memory architecture: Connect multiple individual computers, each with its own processor and memory, via a high-speed network.
We will now explore these approaches in detail.
What do you think the main differences between these two approaches are?
Can you think of any advantages and/or disadvantages for both of them?
 Image courtesy of
Image courtesy of The fundamental feature of a shared-memory computer is that all the CPU-cores are connected to the same piece of memory.

This is achieved by having a memory bus that takes requests for data from multiple sources (here, each of the four separate CPU-cores) and fetches the data from a single piece of memory. The term bus apparently comes from the Latin omnibus meaning for all, indicating that it is a single resource shared by many CPU-cores.
This is the basic architecture of a modern mobile phone, laptop or desktop PC.
If you buy a system with a quad core processor and 4 GBytes of RAM, each of the 4 CPU-cores will be connected to the same 4 Gbytes of RAM, and they’ll therefore have to play nicely and share the memory fairly between each other.
A good analogy here is to think of four office-mates or workers (the CPU-cores) sharing a single office (the computer) with a single whiteboard (the memory).
Each worker has their own set of whiteboard pens and an eraser, but they are not allowed to talk to each other:
they can only communicate by writing to and reading from the whiteboard.
Later in this module, we’ll explore strategies for leveraging this shared whiteboard to enable efficient cooperation among the workers.
However, this analogy already illustrates two key limitations of this approach:
- memory capacity: There is a limit to the size of the whiteboard that you can fit into an office, i.e. there is a limit to the amount of memory you can put into a single shared-memory computer;
- memory access speed: imagine that there were ten people in the same office - although they can in principle all read and write to the whiteboard, there’s simply not enough room for more than around four of them to do so at the same time as they start to get in each other’s way. Although you can fill the office full of more and more workers, their productivity will stall after about 4 workers, as contention for the shared memory bus increases a bottleneck is created.
Limitations
It turns out that memory access speed is a real issue in shared-memory machines.
If you look at the processor diagram above, you’ll see that all the CPU-cores share the same bus: the connection between the bus and the memory becomes a bottleneck, limiting the number of CPU-cores that can efficiently utilize the shared memory.
Coupled with the fact that the variety of programs we run on supercomputers tend to read and write large quantities of data, memory access speed often becomes the primary factor limiting calculation speed, outweighing the importance of the CPU-cores' floating-point performance.
Several strategies have been developed to mitigate these challenges, but the overcrowded office analogy highlights the inherent difficulties when scaling to hundreds of thousands of CPU-cores.
Despite its limitations, shared memory architectures are universal in modern processors. What do you think the advantages are?
Think of owning one quad-core laptop compared to two dual-core laptops - which is more useful to you and why?
 Image courtesy of
Image courtesy of Simple Parallel Calculation
We can investigate a very simple example of how we might use multiple CPU-cores by returning to the calculation we encountered in the first module: computing the average income of the entire world’s population.
If we’re a bit less ambitious and think about several hundred people rather than several billion, we can imagine that all the individual salaries are already written on the shared whiteboard. Let’s imagine that the whiteboard is just large enough to fit 80 individual salaries. Think about the following:
- how could four workers cooperate to add up the salaries faster than a single worker?
- using the estimates of how fast a human is from the previous module, how long would a single worker take to add up all the salaries?
- how long would 4 workers take for the same number of salaries?
- how long would 8 workers take (you can ignore the issue of overcrowding)?
- would you expect to get exactly the same answer as before?
We’ll revisit this problem in much more detail later but you know enough already to start thinking about the fundamental issues.
 Image courtesy of
Image courtesy of Who needs a multicore laptop?
We’ve motivated the need for many CPU-cores in terms of the need to build more powerful computers in an era when the CPU-cores themselves aren’t getting any faster. Although this argument makes sense for the world’s largest supercomputers, we now have multicore laptops and mobile phones - why do we need them?
It may not be apparent until we cover how to parallelise a calculation later on, but it is not usually the case that 2 CPU-cores are twice as fast as 1.
Most computer programs require explicit changes to their code to take advantage of multiple CPU-cores, a process called parallelisation.
This was especially true back in 2005, when multicore CPUs first became widely available and most programs were serial, designed for single-core processors.
Do multi-core processors offer advantages to users running programs that don’t utilize parallel computing? Such programs, operating on a single CPU-core, are called serial programs.
Operating Systems
As a user, you don’t directly assign programs to specific CPU-cores.
The Operating System (OS) acts as an intermediary between you and the hardware, managing access to CPU-cores, memory, and other components.
There are several common OS’s around today - e.g. Windows, macOS, Linux and Android - but they all perform the same basic function: you ask the OS to execute a program, and a component of the OS called the scheduler manages when and on which CPU-core the program is executed.
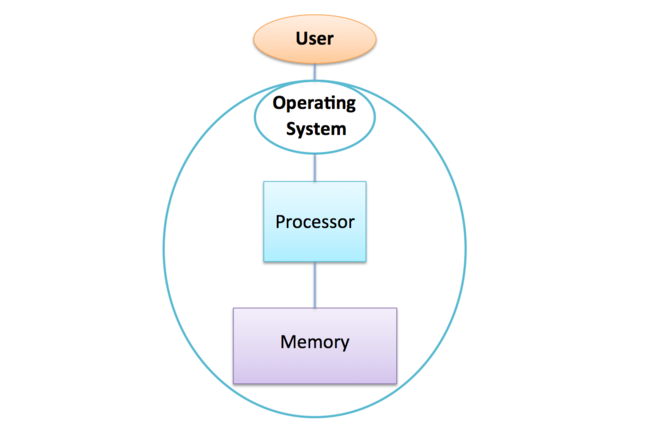
This enables even a single CPU-core machine to appear to be doing more than one thing at once - it will seem to be running dozens of programs at the same time.
What is actually happening is that the OS runs one program, say, for a hundredth of a second, then stops that program and runs another one for a hundredth of a second, etc.
Just like an animation made up of many individual frames, this gives the illusion of continuous motion.
How the OS exploits many CPU-cores
On a shared-memory computer, the important point is that all the CPU-cores are under the control of a single OS (meaning you don’t need to buy 4 Windows licences for your quadcore laptop!).
This means that your computer can genuinely run more than one program at the same time.
It’s a bit more complicated for the OS - it has to decide not just which programs to run but also where to run them - but a good OS performs a juggling act to keep all the CPU-cores busy.
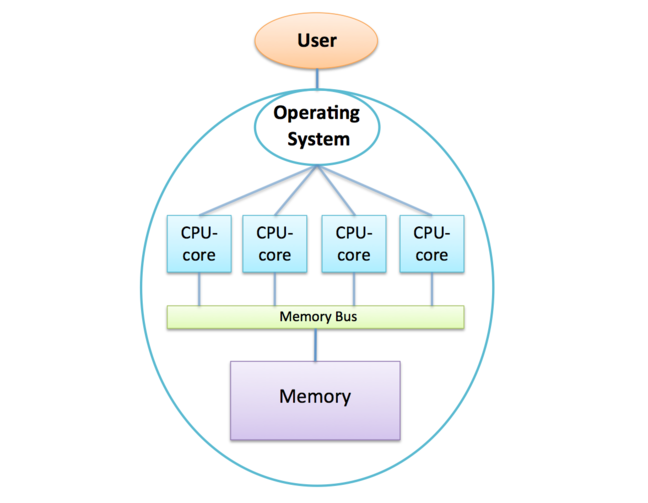
This means that you can run a web browser, listen to music, edit a document and run a spreadsheet all at the same time without these different programs slowing each other down.
With shared memory, the OS can pause a program on CPU-core 1 and resume it later on CPU-core 3, as all CPU-cores can access the same shared memory.
This allows seamless task switching.
A shared-memory computer looks like a more powerful single-core computer: it operates like a single computer because it has a single OS, which fundamentally relies on all the CPU-cores being able to access the same memory. It is this flexibility that makes multicore shared-memory systems so useful.
So, for home use, the Operating System does everything for us, running many separate programs at the same time.
In supercomputing, the goal is to accelerate a single program rather than running multiple tasks simultaneously.
Achieving this requires effort beyond what the OS can provide.
In your opinion what are the downsides of this more advanced ‘single-core computer’ approach?
How does your laptop use multiple CPU-cores?
This video shows a simple demo to illustrate how modern operating systems take advantage of many CPU-cores.
Watch what happens when David runs multiple copies of a simple income calculation program on his quad-core laptop. Do you find this behaviour surprising?
Note that running multiple instances of our toy program simultaneously does not save time.
Each instance runs independently, producing identical results in approximately the same duration.
This demo illustrates how an operating system handles execution on multiple CPU-cores, but otherwise is a waste of resources.
Can you think of a situation in which this kind of execution may be useful?
We haven’t really explained what the concept of minimum interference is about - think of David closing down his browser before running his code - but can you think of a reason why it may be important to isolate your program as much as possible, especially when running on a supercomputer? What are the implications of not doing this?
If you are interested, here is the function that David actually timed.
The function is written in C and is provided purely for reference.
It is not intended to be compiled or executed as it is.
// Add up a given number of salaries to compute total income. // Use floating-point numbers to better represent real calculations. double salarysum(double salarylist[], int npeople) { double total; int i; total = 0.0; for (i=0; i < npeople; i++) { total = total + salarylist[i]; } return total; }
David: I re-ran the same studies covered in the video but with almost all other tasks disabled , for example I did not run the graphical performance monitor, which allowed me to have access to all four CPU-cores. Here are the results.
| dataset | #copies | runtime (seconds) |
|---|---|---|
| small | 1 | 9.7 |
| small | 4 | 11.1 |
| small | 8 | 22.2 |
 Image courtesy of
Image courtesy of Memory Caches
We mentioned before that memory access speeds are a real issue in supercomputing, and adding more and more CPU-cores to the same memory bus just makes the contention even worse.
The standard solution is to have a memory cache. This is basically a small amount of scratch memory on every CPU-core, which is very fast. However, it is also quite small - well under a megabyte when the total memory will be more than a thousand times larger - so how can it help us?
The standard solution is to have a memory cache; a small, high-speed storage area located on each CPU-core. It allows the core to access frequently used data much faster than from main memory.
However, it is also quite small, well under a megabyte, representing less than a thousandth of the total memory.
Think of the analogy with many workers sharing an office: The obvious solution to avoid always queueing up to access the shared whiteboard is to take a temporary copy of what you are working on.
When you need to read data from the whiteboard, you copy the necessary data into your notebook and work independently, reducing contention for the shared resource.
This works very well for a single worker: you can work entirely from your personal notebook for long periods, and then transfer any updated results to the whiteboard before moving on to the next piece of work.
It can also work very well for multiple workers as long as they only ever read data.
Writing data
Unfortunately, real programs also write data, meaning workers need to update the shared whiteboard. If two people are working on the same data at the same time, we have a problem: if one worker changes some numbers in their notebook then the other worker needs to know about it. Whenever you alter a number, you must inform the other workers, for example:
"I’ve just changed the entry for the 231st salary - if you have a copy of it then you’ll need to get the new value from me!"
Although this could work for a small number of workers, it clearly has problems of scalability.
Imagine 100 workers: whenever you change a number you have to let 99 other people know about it, which wastes time.
Even worse, you have to be continually listening for updates from 99 other workers instead of concentrating on doing your own calculation.
This is the fundamental dilemma: memory access is so slow that we need small, fast caches so we can access data as fast as we can process it. However, whenever we write data there is an overhead which grows with the number of CPU-cores and will eventually make everything slow down again.
This process of ensuring consistent and up-to-date data across all CPU-cores is called cache coherency, a critical challenge in multicore processor design.
It ensures we always have up-to-date values in our notebook (or, at the very least, that we know when our notebook is out of date and we must return to the whiteboard).
Keeping all the caches coherent when we write data is the major challenge.
What do you think is the current state-of-the-art? How many CPU-cores do high-end processors have?
Resource Contention
This video shows a simple demo to illustrate what happens when multiple cores try to use the same resources at the same time.
As mentioned earlier, resource contention occurs when multiple CPU-cores attempt to access the same resources, such as memory, disk storage, or network buses.
Here we look at memory access.
Watch what happens when three copies of a larger income calculation program are running on three CPU-cores at the same time. Is this what you expected?
Keep in mind that CPU-cores are affecting each other not by exchanging data, but because they compete for the same data in memory.
In other words, the CPU-cores do not collaborate with each other i.e. they do not share the total work amongst themselves.
Please note that the larger calculation processes 100 million salaries, not 1 million as mistakenly mentioned in the video. — David
For Step 2.6, the calculations are reran with the graphical monitor turned off, allowing access to all 4 CPU-cores.
Here are the timings for this large dataset with the small dataset results included for comparison.
| dataset | #copies | runtime (seconds) |
|---|---|---|
| small | 1 | 9.7 |
| small | 4 | 11.1 |
| small | 8 | 22.2 |
| large | 1 | 10.7 |
| large | 4 | 28.5 |
| large | 8 | 57.0 |
Terminology Quiz
Parallel Computers Q1
A system built from a single multicore processor (perhaps with a few tens of CPU-cores) is an example of the __ __
architecture, whereas a system composed of many separate processors connected via a high-speed network is referred to as the
__ __ architecture.
Parallel Computers Q2
The two main limitations of the shared-memory architecture are: memory __
and memory __ __. The hierarchical memory structure is used to improve the memory access speeds.
The smallest but also the fastest memory is called __ memory.
And keeping the data consistent and up-to-date on all the CPU-cores is called __ __.
Parallel Computers Q3
The situation when multiple CPU-cores try to use the same resources, e.g. memory, disk storage or network buses, is called __ __.