Comparing the Two Approaches
Comparing the two approaches
Looking inside your laptop
We’ve explained that the hardware building blocks of supercomputers, memory and processors, are the same as for general-purpose computers.
But ARCHER looks very different from your laptop!
In this video David deconstructs a laptop so that we can compare its packaging to the specialist design of a supercomputer.
How similar is your laptop to a node of a supercomputer?
Next, in this video, David takes apart a compute blade from the HECToR supercomputer.
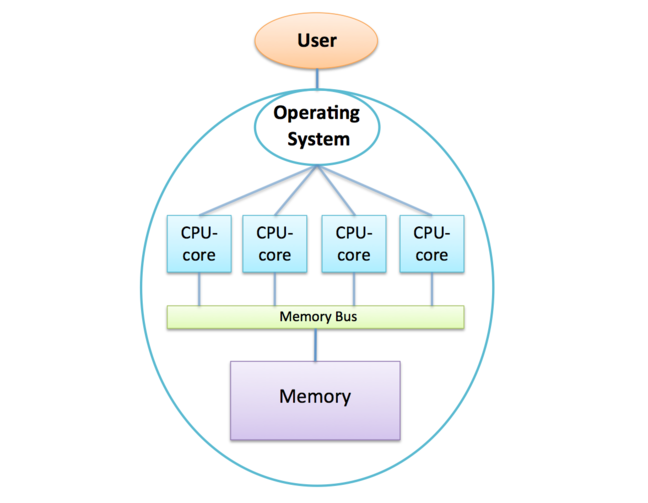
Do you remember this diagram?

Having watched the above video, how would you modify it to make it more accurate?
 © Cray Inc
© Cray Inc HECToR's compute blades
HECToR's compute blades Image courtesy of
Image courtesy of We’ve seen how individual CPU-cores can be put together to form large parallel machines in two fundamentally different ways: the shared and distributed memory architectures.
In the shared-memory architecture all the CPU-cores can access the same memory and are all controlled by a single operating system. Modern processors are all multicore processors, with many CPU-cores manufactured together on the same physical silicon chip.
There are limitations to the shared-memory approach due to all the CPU-cores competing for access to memory over a shared bus.
This can be alleviated to some extent by introducing memory caches or putting several processors together in a NUMA architecture, but there is no way to reach the hundreds of thousands of CPU-cores with this approach.
In the distributed-memory architecture, we take many multicore computers and connect them together in a network.
With a sufficiently fast network we can in principle extend this approach to millions of CPU-cores and beyond.
Shared-memory systems are difficult to build but easy to use, and are ideal for laptops and desktops.
Distributed-memory systems are easier to build but harder to use, comprising many shared-memory computers each with their own operating system and their own separate memory.
However, this is the only feasible architecture for constructing a modern supercomputer.
These are the two architectures used today. Do you think there is any alternative? Will we keep using them for evermore?
 Image courtesy of
Image courtesy of What limits the speed of a supercomputer?
When we talked about how fast modern processors are, we concentrated on the clock frequency (nowadays measured in GHz, i.e. in billions of operations per second) which grew exponentially with Moore’s law until around 2005.
However, with modern distributed-memory supercomputers, two additional factors become critical:
- CPU-cores are packaged together into shared-memory multicore nodes, so the performance of memory is important to us;
- separate nodes communicate over a network, so network performance is also important.
Latency and bandwidth
Understanding memory and network performance is useful in order to grasp the practical limitations of supercomputing.
We’ll use the ARCHER system to give us some typical values of the two basic measures.
Latency and bandwidth:
- latency is the minimum time required to initiate a data transfer, such as transferring a single byte. This overhead is incurred regardless of the amount of data being handled.
- bandwidth is the rate at which large amounts of data can be transferred.
A helpful analogy is to compare this to an escalator.
The time it takes a single person to travel from the bottom to the top is its latency — around 10 seconds for one trip.
However this does not mean the escalator can only transport one person every ten seconds, the escalator can accommodate multiple people simultaneously, allowing several people to reach the top each second.
This is its bandwidth.
Numbers from ARCHER2
For access to memory (not cache! - access to cache is faster), the latency (delay between asking for a byte of data and reading it) is around 80 nanoseconds (80 x 10-9 or 80 billionths of a second). On ARCHER2, each node has a bandwidth of around 200 GBytes/second.
These figures might sound impressive, but remember that at a clock speed of around 2.7 GHz, each CPU-core is issuing instructions roughly every 0.4 nanoseconds, so waiting for data from memory takes the equivalent of around 200 instructions!
Remember also that, on ARCHER2, 128 CPU-cores are sharing access to memory so this latency can only increase due to congestion on the memory bus.
Bandwidth is also shared, giving each CPU-core just over 3 GBytes/second on average.
At a 2.7 GHz clock frequency, this implies that, in the worst-case scenario where all CPU-cores access memory simultaneously, each core can read or write just one byte per cycle.
A simple operation such as a = b + c processes 24 bytes of memory (read a and b, write c, each floating-point number occupying 8 bytes) so we are a long way off being able to supply the CPU-core with data at the rate it requires.
In practice, cache memory significantly mitigates these issues by providing much lower latency and higher bandwidth but back-of-the-envelope calculations, such as we have done above, do illustrate an important point about supercomputer design:
The performance of the processors in a modern supercomputer is limited by the memory bandwidth and not the clock frequency.
Interconnect Archer2
ARCHER2 has a very high-performance network with the following characteristics:
- a latency of around 2 microseconds (2 x 10-6 or 2 millionths of a second);
- a bandwidth between 2 nodes of around 25 GBytes/second.
With a latency of 2 microseconds corresponding to approximately 5000 instruction cycles, even ARCHER2's high-speed network introduces a significant overhead for communication.
While the bandwidth is shared among all CPU-cores on a node, ARCHER2's thousands of separate network links collectively enable the transfer of many TBytes/second.
We will see in the next module that if we are careful about how we split our calculation up amongst all the CPU-cores we can mitigate these overheads to a certain extent, enabling real programs to run effectively on tens of thousands of cores.
Despite this, it is still true that:
The maximum useful size of a modern supercomputer is limited by the performance of the network.
Large internet companies like Amazon and Google also use distributed memory architectures for their computational needs. They also offer access to their machines via something known as cloud computing. Do you think Amazon and Google services have the same requirements as we do in supercomputing? What limits the performance of their computers? Are they interested in Pflops?
 Image courtesy of
Image courtesy of Graphics Processors
When looking at the top500 list, you may have noticed that many of the world’s largest supercomputers use some kind of accelerator in addition to standard CPUs.
A popular accelerator is a General Purpose Graphics Processing Unit, or GPGPU.
Since we have sen how a modern multicore CPU works, we can also begin to understand the design of a GPGPU.
Supercomputers have traditionally relied on general-purpose components, primarily multicore CPUs, driven by commercial demand for desktop and business computing.
However, computer gaming also significant market where processor performance is critical.
The massive demand for computer games hardware has driven the development of specialized processors - Graphics Processing Units (GPUs) — designed to produce high-quality 3D graphics.
Although complex in design, a GPU can be thought of as a specialized multicore processor with a vast number of simplified cores.
The cores can be simplified because they have been designed for a single purpose: 3D graphics.
To render high-quality graphics at dozens of frames per second, GPUs require the ability to process massive amounts of data.
To achieve this, they utilize specialised memory with significantly higher bandwidth than the memory typically used by CPUs.
The simplified nature of each core, the much higher number of cores, and the high memory bandwidth means that the performance, in terms of pure number crunching, of a single GPU can easily outstrip that of a CPU at the expense of it being less adaptable.
Accelerated supercomputers
Despite being developed for a different purpose, GPUs are highly suited for supercomputing: The calculations required for 3D graphics are very similar to those required for scientific simulations - large numbers of simple operations on huge quantities of floating-point numbers.
- designed for very fast floating-point calculation;
- power-efficient due to the simple core design;
- high memory bandwidth to keep the computational cores supplied with data.
The inherently parallel architecture of GPUs, with thousands of computational cores, aligns well with the decades-long focus on parallel processing in supercomputing.
Using GPUs for applications other than graphics is called General Purpose or GPGPU computing. With a relatively small amount of additional development effort, GPU manufacturers produce versions of their processors for the general purpose market.
The supercomputing community directly benefits from the multi-billion pound research and development investments in the games market.
Programming a GPGPU isn’t quite as straightforward as a CPU, and not all applications are suitable for its specialised architecture, but one of the main areas of research in supercomputing at the moment is making GPGPUs easier to program for supercomputing applications.
Earlier we asked you to look at Piz Daint, which is accelerated compared to ARCHER2 by the addition of Nvidia’s GPGPUs. Use the sublist generator on the top500 page to check how many top500 systems use Nvidia accelerators. Do you see what you expected to see?
terminology Recap
Comparing the Two Approaches Q1
One of the differences between the shared and distributed memory architectures is that shared-memory systems are managed by only one
__ __, whereas distributed memory systems have many of them (typically one per node).
Comparing the Two Approaches Q2
The two basic measures characterising the memory and network performance are: __
and __ .
__ is the rate at which you transfer large amounts of data.
__ is the minimum time taken to do anything at all, i.e. the time taken to transfer a single byte.
Comparing the Two Approaches Q3
In the distributed memory architecture, the only way that two nodes can interact with each other is by communicating over the
__. In the shared memory architecture, different CPU-cores can communicate with each other by updating the same __ location.
 Image courtesy of
Image courtesy of Game: Build your own supercomputer
In this game you are in charge of a supercomputer centre and you have to run lots of users’ jobs on your machine. Use your budget wisely to buy the best hardware for the job!
The main idea behind the game is to create a design of a supercomputer, balancing its components against budget and power efficiency.
Creating an efficient design may be difficult, however worry not! It’s a game after all. You are welcome to play it again at any time during the course. It may be interesting to see how your understanding of supercomputers improved.
Your design must handle jobs, and the completion of these provides money which can be further invested. As you progress through the levels the jobs become more complex (and lucrative) and additional components are available to be included within the machine. Besides passing through the levels, you can also obtain badges that are awarded for specific achievements such as a green supercomputer, profitable machine and the overall number of jobs run.
Follow the link to the game and start playing. We recommend doing a quick walk through first - click the ? icon on the landing page. You can summon the help menu at any point in the game by clicking on the Info icon, located in the upper right corner of the screen.
We hope you will enjoy your experiences as a supercomputing facility manager, good luck!