Parallelising Mandelbrot Set Generation
Part 1: Introduction & Theory
Mandelbrot Set
The Mandelbrot set is a famous example of a fractal in mathematics. It is a set of complex numbers for which the function
does not diverge to infinity when iterated from , i.e the values of for which the sequence
remains bounded.
The complex numbers can be thought of as 2d coordinates, that is a complex number with real part and imaginary part () can be written as . The coordinates can be plotted as an image, where the color corresponds to the number of iterations required before the escape condition is reached. The escape condition is when we have confirmed that the sequence is not bounded, this is when the magnitude of , the current value in the iteration, is greater than 2.
The complex numbers can be thought of as 2d coordinates, that is a complex number with real part and imaginary part () can be written as .
The coordinates can be plotted as an image, where the color corresponds to the number of iterations required before the escape condition is reached; when we have confirmed that the sequence is not bounded, this is when the magnitude of , the current value in the iteration, is greater than 2.
The pseudo code for this is:
for each x,y coordinate x0, y0 = x, y x = 0 y = 0 iteration = 0 while (iteration < max_iterations and x^2 + y^2 <= 4 ) x_next = x^2+y^2 + x0 y_next = 2*x*y + y0 iteration = iteration + 1 x = x_next y = y_next return color_map(iteration)
Note that for points within the Mandelbrot set
the condition will never be met, hence the need to set the upper bound
max_iterations.The Julia set is another example of a complex number set.
From the parallel programming point of view the useful feature of the Mandelbrot and Julia sets is that the calculation for each point is independent i.e. whether one point lies within the set or not is not affected by other points.
Parallel Programming Concepts
Task farm
Task farming is one of the common approaches used to parallelise applications. Its main idea is to automatically create pools of calculations (called tasks), dispatch them to the processes and the to collect the results.
The process responsible for creating this pool of jobs is known as a source, sometimes it is also called a master or controller process.
The process collecting the results is called a sink. Quite often one process plays both roles – it creates, distributes tasks and collects results. It is also possible to have a team of source and sink process. A ‘farm’ of one or more workers claims jobs from the source, executes them and returns results to the sink. The workers continually claim jobs (usually complete one task then ask for another) until the pool is exhausted.
Figure 1 shows the basic concept of how a task farm is structured.
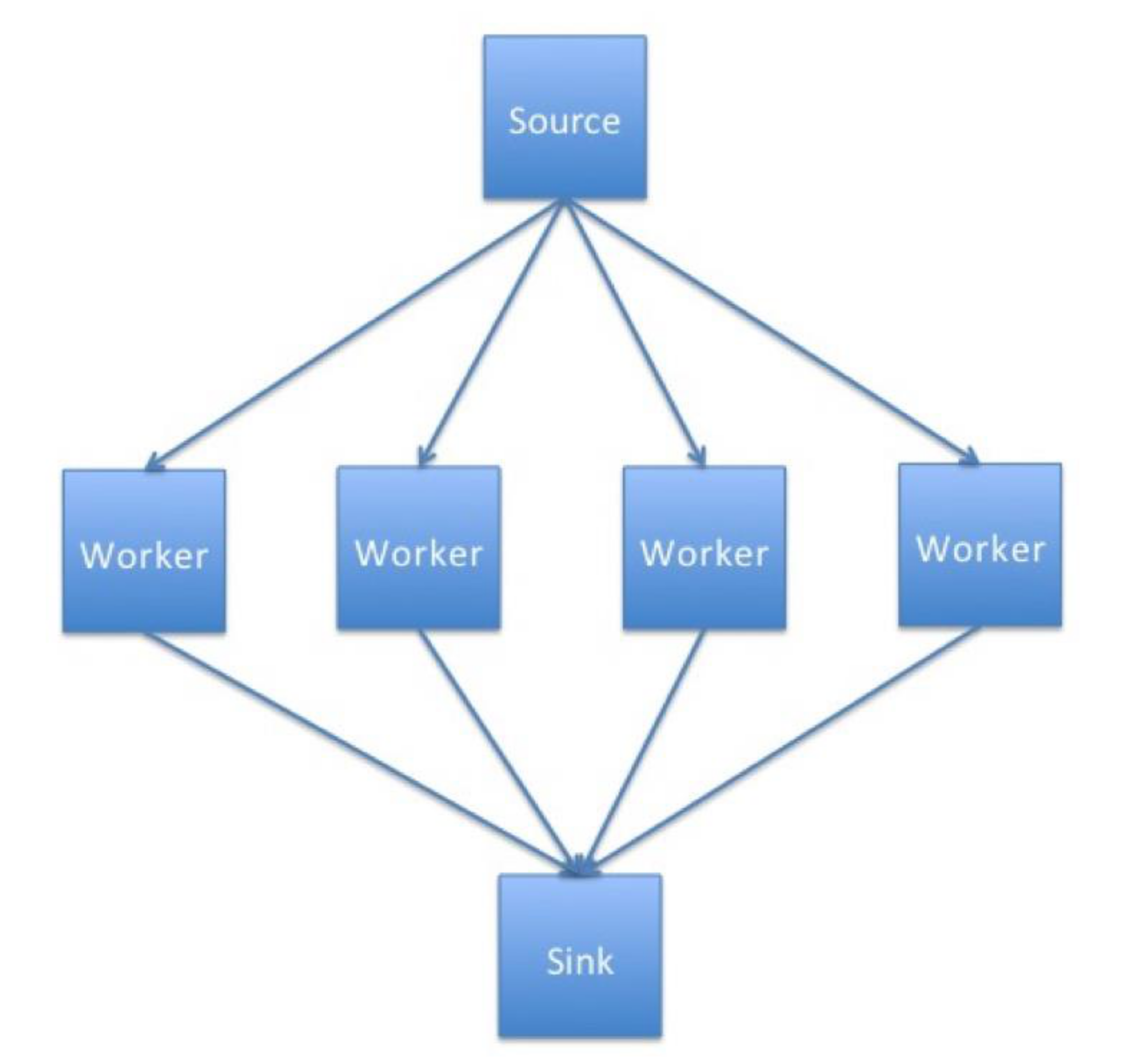 Schematic representation of a simple task farm
Schematic representation of a simple task farmIn summary processes can assume the following roles:
- Source - creates and distributes tasks
- Worker processes - complete tasks received from the source process and then send results to the sink process
- Sink - gathers results from worker processes.
Having learned what a task farm is, consider the following questions:
- What types of problems could be parallelised using the task farm approach? What types of problems would not benefit from it? Why?
- What kind of computer architecture could fully utilise the task farm benefits?
Using a task farm
A task farm is commonly used in large computations composed of many independent calculations.
Only when calculations are independent is it possible to assign tasks in the most effective way, and thus speed up the overall calculation with the most efficiency.
If the tasks are independent from each other, the processors can request them as they become available, i.e. usually after they complete their current
task, without worrying about the order in which tasks are completed.
The dynamic allocation of tasks is an effective method for getting more use out of the compute resources.
It is inevitable that some calculations will take longer to complete than others, so using methods such as a lock-step calculation (waiting on the whole set of processors to finish a current job) or pre-distributing all tasks at the beginning would lead to wasted compute cycles.
Of course, not all problems can be parallelised using a task farm approach.
Not always a task farm
While many problems can be broken down into individual parts, there are a sizeable number of problems where this approach will not work.
Problems which involve lots of inter-process communication are often not suitable for task farms as they require the master to track which worker has which element, and to tell workers which other workers they are required to communicate with.
Additionally, the sink process may need to track this as well in cases of output order dependency.
It is still possible to use task farms to parallelise problems that require a lot of communications, however, in such cases additional complexity or overheads impacting the performance can be incurred.
As mentioned before, to determine the points lying within the Mandelbrot set there is no need for the communications between the worker tasks, which makes it an embarrassingly parallel problem that is suitable for task-farming.
Even knowing a task-farm is viable for a given job, we still need to consider how to use it in the most optimal way.
- How do you think the performance would be affected if you were to use more, equal and fewer tasks than workers?
- In your opinion what would be the optimal combination of the number of workers and task? What would it depend on the most? Task size? Problem size? Computer architecture?
Load Balancing
The factor deciding the effectiveness of a task farm is a task distribution.
Determining how the tasks are distributed across the workers is called a balancing.
Successful load balancing avoids overloading a single worker, maximising the throughput of the system and making best use of resources available.
Poor load balancing will cause some workers of the system to be idle and consequently other elements to be ‘overworked’, leading to increased
computation time and significantly reduced performance.
Poor load balancing
The figure below shows how careless task distribution can affect the completion time.
Clearly, CPU2 needs more time to complete its assigned tasks, particularly compared to CPU3.
The total runtime is equivalent to the longest runtime on any of the CPUs so the calculation time will be longer than it would be if the resources
were used optimally.
This can occur when load balancing is not considered, random scheduling is used (although this is not always bad), or poor decisions are made about the job sizes.
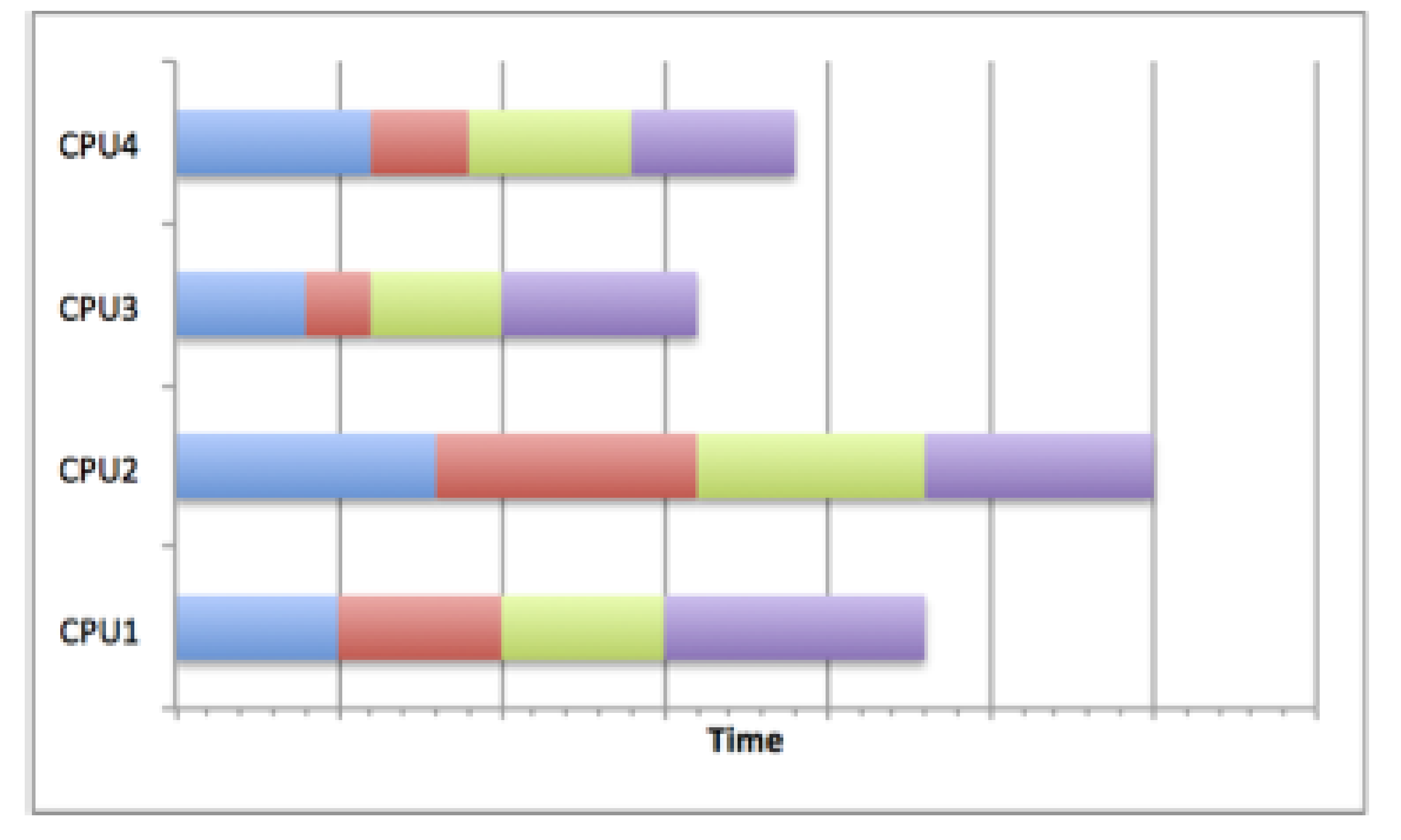 Poor load balance
Poor load balanceGood Load Balancing
The next figure below shows how by scheduling jobs carefully, the best use of the resources can be made.
When a distribution strategy is chosen which optimises the use of resources, the CPUs in the diagram complete their tasks at roughly the same time.
This means that no one worker has been overloaded with tasks and dominated the running time of the overall calculation.
This can be achieved by many different means.
For example, if the task sizes and running times are known in advance, the jobs can be scheduled to allow best resource usage.
The most common strategy is to distribute large jobs first and then distribute progressively smaller jobs to equal out the workload.
In general, the smaller the individual tasks there are the easier it is to balance the load between the workers, however, the more tasks there are to distribute the more load is generated for the source and sink processes.
If the job sizes can change or the running times are unknown, then an adaptive system could be used which tries to infer future task lengths based upon observed runtimes.
 Good load balance
Good load balanceThe fractal program you will be using employs a queue strategy – tasks are queued waiting for workers, which completed their previous task, to claim them from the top of the queue.
This ensures that workers that are assigned shorter tasks will complete more tasks and finish roughly at the same time as workers with longer tasks.
Quantifying the load imbalance
We can try to quantify how well balanced a task farm is by computing the load imbalance factor, which we define as:
For a perfect load-balanced calculation this will be equal to 1.0, which occurs when all workers have exactly the same amount of work.
In practice, it will always be greater than 1.0.
The load imbalance factor can be a useful measure; it allows you to predict what the runtime would be for a perfectly balanced load on the same number of workers - assuming that no additional overheads are introduced by the load balancing.
For example, if the load imbalance factor is 2.0 we could reduce the runtime by up to a factor of 2 if the load were perfectly balanced.
Part 2: Compile and Run
Let's compile and run the example fractal code which makes use of MPI.
Compiling the source code
cd foundation-exercises/fractal/C-MPI ls
Similarly to the previous examples, we can compile the serial source code by doing:
make
Again, if running this on your own machine locally, you may need to edit the
Makefile to change the compiler used. You can then run the code directly with mpiexec, e.g. mpiexec -n 4 ./fractal to run it with 4 processes.If you're running this on ARCHER2 you'll note that the created executable
fractal cannot be run directly, since if you try you get:ERROR: need at least two processes for the task farm!
Submitting a Fractal MPI job
To be able to run the job submission examples in this segment, you'll need to either have access to ARCHER2, or similar HPC infrastructure running the Slurm job scheduler and knowledge of how to configure job scripts for submission.
So on an HPC infrastructure, we'll need (and should!) submit this as a job via Slurm.
Write a script that executes the fractal MPI code that uses 16 worker processes on a single node.
Once complete, you should find the log file contains something like the following:
--------- CONFIGURATION OF THE TASKFARM RUN --------- Number of processes: 17 Image size: 768 x 768 Task size: 192 x 192 (pixels) Number of iterations: 5000 Coordinates in X dimension: -2.000000 to 1.000000 Coordinates in Y dimension: -1.500000 to 1.500000 -----Workload Summary (number of iterations)--------- Total Number of Workers: 16 Total Number of Tasks: 16 Total Worker Load: 498023053 Average Worker Load: 31126440 Maximum Worker Load: 156694685 Minimum Worker Load: 62822 Time taken by 16 workers was 0.772049 (secs) Load Imbalance Factor: 5.034134
The
fractal executable will take a number of parameters and produce a fractal image in a file called output.ppm. By default the image will be
overlaid with blocks in different shades, which correspond to the work done by different processors. This way we can see how the tasks were allocated. An example of this is presented in figure 1 – the image is divided into 16 tasks (squares) and a different shade of red corresponds to each of the workers. For example, running this on ARCHER2 with 16 workers will therefore yield 16 shades of red, and running this on your own machine with 4 workers will yield 4 shades instead. Example output image created using 16 workers and 16 tasks.
Example output image created using 16 workers and 16 tasks.So in our example script, the program created a task farm with one master process and 2 workers. The master divides the image up into tasks, where each task is a square of the size of 192 by 192 pixels (the default size of each square). The default image size is thus 768 x 768 pixels, which means there is exactly 1 task per worker.
The load of a worker is estimated as the total number of iterations of the Mandelbrot calculation summed over all the pixels considered by that worker. The assumption is that the time taken is proportional to this. The only time that is actually measured is the total time taken to complete the calculation.
If on ARCHER2, use
scp to copy the output.ppm image file back to your local machine to view it, otherwise if on your own machine open the file directly. In any event, your "pattern" of workers for each segment will likely differ than what's depicted here, depending on which workers were assigned which task and how many workers you used.Removing Diagnostic Output
Try adding
-n to fractal's arguments in the submission script. What happens?Fractal Program Parameters
The following options are recognised by the fractal program:
-Snumber of pixels in the x-axis of image-Imaximum number of iterations-xthe x-minimum coordinate-ythe y-minimum coordinate-f <fractal function>set to J for Julia set-cthe real part of the parameter c+iC for the Julia set-Cthe imaginary part of the parameter c+iC for the julia set-ttask size (pixels x pixels)-ndo not shade output image based on task allocation to workers
Part 3: Investigation
For this segment, if you're running this locally on your own machine assume 3 workers (and 1 master process) instead of 16 workers (and 1 master process), since it's quite possible your own machine will not be able to handle 17 parallel MPI processes over 17 separate cores.
To explore the effect of load balancing run the code with different parameters and try to answer the following questions.
Predict Runtime
From the default run with 16 workers and 16 tasks, what is your predicted best runtime based on the load imbalance factor?
Load Distribution
Look at the output for 16 tasks – can you understand how the load was distributed across workers by looking at the colours of the bands and the structure of the Mandelbrot set?
Exploring Load Imbalance
For 16 workers, run the program with ever smaller task sizes (i.e. more tasks) and create a table with each row containing grid size, runtime, and load imbalance factor. You should ensure you measure all the way up to the maximum number of tasks, i.e. a task size of a single pixel.
You can use
-t as an argument to the fractal program to set the task/grid size.Analysis
Can you explain the form of the table/graph?
Does the minimum runtime approach what you predicted from the load imbalance factor?